A Usable Copy-Paste Detector in A Few Lines of Python
by Yannick Moy , Emmanuel Briot , Nicolas Roche –
After we created lightweight checkers based on the recent Libadalang technology developed at AdaCore, a colleague gave us the challenge of creating a copy-paste detector based on Libadalang. It turned out to be both easier than anticipated, and much more efficient and effective than we could have hoped for. In the near future, we plan to use this new detector to refactor the codebase of some of our tools.
First Attempt: Hashes and Repeated Suffix Trees
Our naive strategy for detecting copy-paste was to reduce it to a string problem, in order to benefit from the existing efficient algorithms on string problems. Our reasoning was that each line of code could be represented by a hash code, so that a file could be represented by a string of hash codes. After a few Web searches, we found the perfect match for this translated problem, on the WikiPedia page for the longest repeated substring problem, which is helpfully pointing to a C implementation used to solve this problem efficiently based on Suffix Trees, a data structure to represent efficiently all suffixes of a string (say, "adacore", "dacore", "acore", "core", "ore", "re" and "e" if your string is "adacore").
So we came up with an implementation in Python of the copy-paste detector, made up of 3 steps:
Step 1: Transform the source code into a string of hash codes
This a simple traversal of the AST produced by Libadalang, producing roughly a hash for each logical line of code. Traversal is made very easy with the API offered by Libadalang, as each node of the AST is iterable in Python to get its children. For example, here is the default case of the encoding function producing the hash codes:
# Default case, where we hash the kind of the first token for the node,
# followed by encodings for its subnodes.
else:
return ([Code(hash(node.token_start.kind), node, f)] +
list(itertools.chain.from_iterable(
[enc(sub) for sub in node])))We recurse here on the AST to concatenate the substrings of hash codes computed for subnodes. The leaf case is obtained for expressions and simple statements, for which we compute a hash of a string obtained from the list of tokens for the node. The API of Libadalang makes it very easy, using again the ability to iterate over a node to get its children. For example, here is the default case of the function computing the string from a node:
return ' '.join([node.token_start.kind]
+ [strcode(sub) for sub in node])We recurse here on the AST to concatenate the kind of the first token for the node with the substrings computed for subnodes. Of course, we are not interested in exactly representing each line of code in this representation. For example, we represent all identifiers by a special wildcard character $, in order to detect copy-pastes even when identifiers are not the same.
Step 2: Construct the Suffix Tree for the string of hash codes
The algorithm by Ukkonen is quite subtle, but it was easy to translate an existing C implementation into Python. For those curious enough, a very instructive series of 6 blog posts leading to this implementation describes Ukkonen's algorithm in details.
Step 3: Compute the longest repeated substring in the string of hash codes
For that, we look at the internal node of the Suffix Tree constructed above with the greatest height (computed in number of hashes). Indeed, this internal node corresponds to two or more suffixes that share a common prefix. For example, with string "adacore", there is a single internal node, which corresponds to the common prefix "a" for suffixes "adacore" and "acore", after which the suffixes are different. The children of this internal node in the Suffix Tree contain the information of where the suffixes start in the string (position 0 for "adacore" and 2 for "acore"), so we can compute positions in the string of hash codes where hashes are identical and for how many hash codes. Then, we can translate this information into files, lines of code and number of lines.
The steps above allow to detect only the longest copy-paste across a codebase (in terms of number of hash codes, which may be different from number of lines of code). Initially, we did not find a better way to detect all copy-pastes longer than a certain limit than to repeat steps 2 and 3 after we remove from the string of hash codes those that correspond to the copy-paste previously detected. This algorithm ran in about one hour on the full codebase of GPS, consisting in 350 ksloc (as counted by sloccount), and it reported both very valuable copy-pastes of more than 100 lines of code, as well as spurious ones. To be clear, the spurious ones were not bugs in the implementation, but limitations of the algorithm that captured "copy-pastes" that were valid duplications of similar lines of code. Then we improved it.
Improvements: Finer-Grain Encoding and Collapsing
The imprecisions of our initial algorithm came mostly from two sources: it was sometimes ignoring too much of the source code, and sometimes too little. That was the case in particular for the abstraction of all identifiers as the wildcard character $, which led to spurious copy-pastes where the identifiers were semantically meaningful and could not be replaced by any other identifier. We fixed that by distinguishing local identifiers that are abstracted away from global identifiers (from other units) that are preserved, and by preserving all identifiers that could be the names of record components (that is, used in a dot notation like Obj.Component). Another example of too much abstraction was that we abstracted all literals by their kind, which again lead to spurious copy-pastes (think of large aggregates defining the value of constants). We fixed that by preserving the value of literals.
As an example of too little abstraction, we got copy-pastes that consisted mostly of sequences of small 5-to-10 lines subprograms, which could not be refactored usefully to share common code. We fixed that by collapsing sequences of such subprograms into a single hash code, so that their relative importance towards finding large copy-pastes was reduced. We made various other adjustments to the encoding function to modulate the importance of various syntactic constructs, simply by producing more or less hash codes for a given construct. An interesting adjustment consisted in ignoring the closing tokens in a construct (like the "end Proc;" at the end of a procedure) to avoid having copy-pastes that start on such meaningless starting points. It seems to be a typical default of token-based approaches, that our hash-based approach allows to solve easily, by simply not producing a hash for such tokens.
After these various improvements, the analysis of GPS codebase came down to 2 minutes, an impressive improvement from the initial one hour! The code for this version of the copy-paste detector can be found in the GitHub repository of Libadalang.
Optimizations: Suffix Arrays, Single Pass
To improve on the above running time, we looked for alternative algorithms for performing the same task. And we found one! Suffix Arrays are an alternative to Suffix Trees, which is simpler to implement and from which we saw that we could generate all copy-pastes without regenerating the underlying data structure after finding a given copy-paste. We implemented in Python the algorithm in C++ found in this paper, and the code for this alternative implementation can be found in the GitHub repository of Libadalang. This version found the same copy-pastes as the previous one, as expected, with a running time of 1 minute for the analysis of GPS codebase, a 50% improvement!
Looking more closely at the bridges between Suffix Trees and Suffix Arrays (essentially you can reconstruct one from the other), we also realized that we could use the same one-pass algorithm to detect copy-pastes with Suffix Trees, instead of recreating each time the Suffix Tree for the text where the copy-paste just detected had been removed. The idea is that, instead of repeatedly detecting the longest copy-paste on a newly created Suffix Tree, we traverse the initial Suffix Tree and issue all copy-pastes with a maximal length, where copy-pastes that are not maximal can be easily recognized by checking the previous hash in the candidate suffixes. For example, if two suffixes for this copy-paste start at indexes 5 and 10 in the string of hashes, we check the hashes at indexes 4 and 9: if they are the same, then the copy-paste is not maximal and we do not report it. With this change, the running time for our original algorithm is just above 1 minute for the analysis of GPS codebase, i.e. close to the alternative implementation based on Suffix Arrays.
So we ended up with two implementations for our copy-paste detector, one based on Suffix Trees and one based on Suffix Arrays. We'll need to experiment further to decide which one to keep in a future plug-in for our GPS and GNATbench IDEs.
Results on GPS
The largest source base on which we tried this tool is our IDE GNAT Programming Studio (GPS). This is about 350'000 lines of source code. It uses object orientation, tends to have medium-sized subprograms (20 to 30 lines), although there are some much longer ones. In fact, we aim at reducing the size of the longest subprograms, and a tool like gnatmetric will help find them. We are happy to report that most of the code duplication occurred in recent code, as we are transitioning and rewriting some of the old modules.
Nonetheless, the tool helped detect a number of duplicate chunks, with very few spurious detections (corresponding to cases where the tool reports a copy-paste that turns out to be only similar code).
Let's take a look at three copy-pastes that were detected.
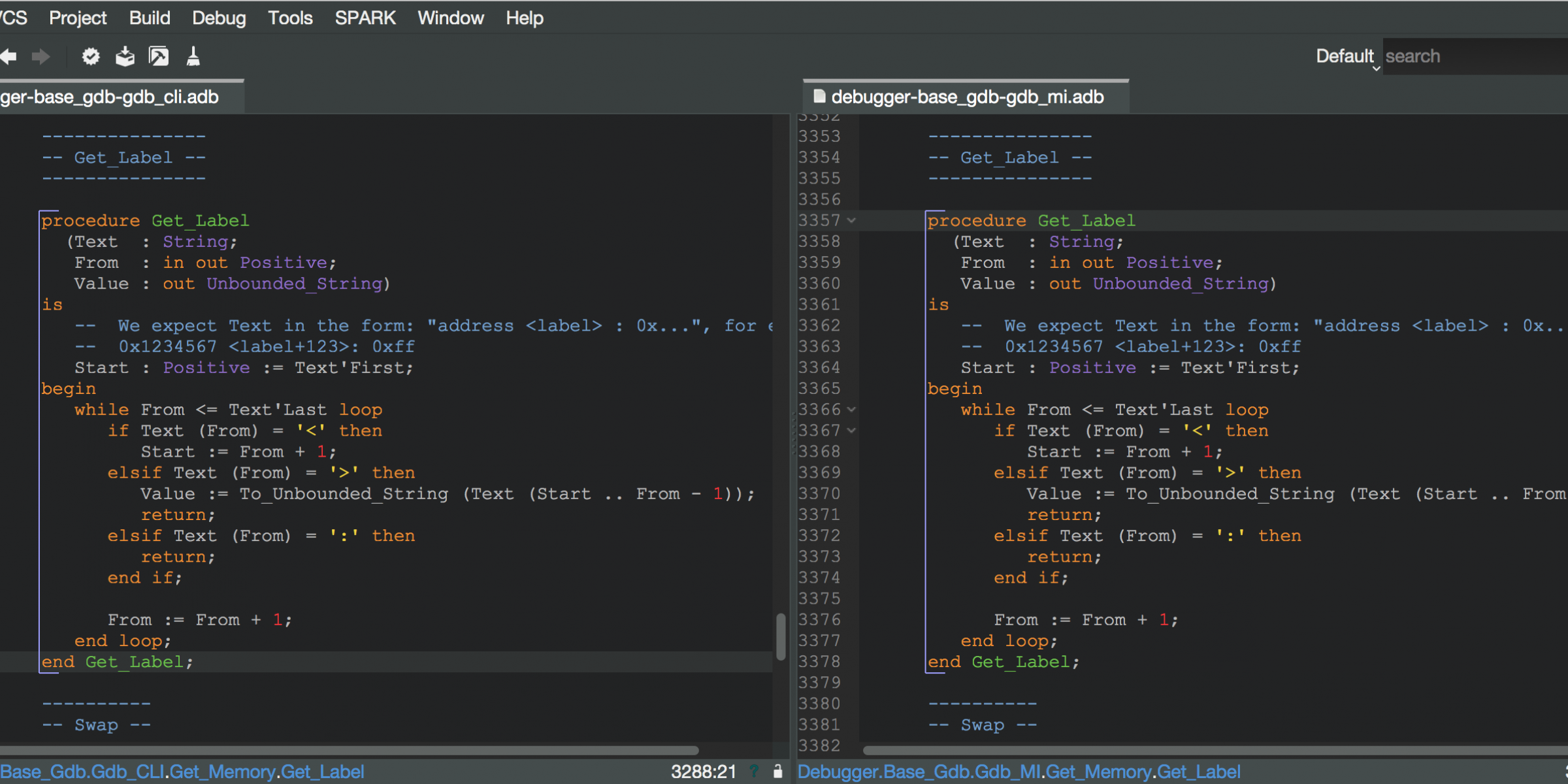
Example 1: Intended temporary duplication of code
gps/gvd/src/debugger-base_gdb-gdb_cli.adb:3267:1: copy-paste of 166 lines detected with code from line 3357 to line 3522 in file gps/gvd/src/debugger-base_gdb-gdb_mi.adb
This is a large subprogram used to handle the Memory view in GPS. We have recently started changing the code to use the gdb MI protocol to communicate with gdb, rather than simulate an interactive session. Since the intent is to remove the old code, the duplication is not so bad, but is useful in reminding us we need to clean things up here, preferably soon before the code diverges too much.
Example 2: Unintended almost duplication of code
gps/builder/core/src/commands-builder-scripts.adb:266:1: copy-paste of 21 lines detected with code from line 289 to line 309
This code is in the handling of the python functions GPS.File.compile() and GPS.File.make(). Interestingly enough, these two functions were not doing the same thing initially, and are also documented differently (make attempts to link the file after compiling it). Yet the code is almost exactly the same, except that GPS does not spawn the same build target (see comment in the code below). So we could definitely use an if-expression here to avoid the duplication of the code.
elsif Command = "compile" then
Info := Get_Data (Nth_Arg (Data, 1, Get_File_Class (Kernel)));
Extra_Args := GNAT.OS_Lib.Argument_String_To_List
(Nth_Arg (Data, 2, ""));
Builder := Builder_Context
(Kernel.Module (Builder_Context_Record'Tag));
Launch_Target (Builder => Builder,
Target_Name => Compile_File_Target, -- <<< use Build_File_Target here for "make"
Mode_Name => "",
Force_File => Info,
Extra_Args => Extra_Args,
Quiet => False,
Synchronous => True,
Dialog => Default,
Via_Menu => False,
Background => False,
Main_Project => No_Project,
Main => No_File);
Free (Extra_Args);The tool could be slightly more helpful here by highlighting the exact differences between the two blocks. As the blocks get longer, it is harder to spot a change in one identifier (as is the case here). This is where an integration in our IDEs like GPS and GNATbench would be useful, and of course possibly with some support for automatic refactoring of the code, also based on Libadalang.
Example 3: Unintended exact duplication of code
gps/code_analysis/src/codepeer-race_details_models.adb:39:1: copy-paste of 20 lines detected with code from line 41 to line 60 in file gps/code_analysis/src/codepeer-race_summary_models.adb
This one is an exact duplication of a function. The tool could perhaps be slightly more helpful by showing those exact duplicates first, since they will often be the easiest ones to remove, simply by moving the function to the spec.
function From_Iter (Iter : Gtk.Tree_Model.Gtk_Tree_Iter) return Natural is
pragma Warnings (Off);
function To_Integer is
new Ada.Unchecked_Conversion (System.Address, Integer);
pragma Warnings (On);
begin
if Iter = Gtk.Tree_Model.Null_Iter then
return 0;
else
return To_Integer (Gtk.Tree_Model.Utils.Get_User_Data_1 (Iter));
end if;
end From_Iter;Setup Recipe
So you actually want to try the above scripts on your own codebase? This is possible right now with your latest GNAT Pro release or the latest GPL release for community & academic users! Just follow the instructions we described in the Libadalang repository, you will then be able to run the scripts inside your favorite Python2 interpreter.
Conclusion
What we took from this experiment was that: (1) it is easier than you think to develop a copy-paste detector for your favorite language, and (2) technology like Libadalang is key to facilitate the necessary experiments that lead to an efficient and effective detector. On the algorithmic side, we think it's very beneficial to use a string of hash codes as intermediate representation, as this allows to precisely weigh in which language constructs contribute what.
Interestingly, we did not find other tools or articles describing this type of intermediate approach between token-based approaches and syntactic approaches, which provides an even faster analysis than token-based approaches, while avoiding their typical pitfalls, and allows fine-grained control based on the syntactic structure, without suffering from the long running time typical of syntactic approaches.
We look forward to integrating our copy-paste detector in GPS and GNATbench, obviously initially for Ada, but possibly for other languages as well (for example C and Python) as progress on langkit, the Libadalang's underlying technology, allows. The integration of Libadalang in GPS was completed not long ago, so it's easier than ever.
About Yannick Moy

Yannick Moy is Head of the Static Analysis Unit at AdaCore. Yannick contributes to the development of SPARK, a software source code analyzer aiming at verifying safety/security properties of programs. He frequently talks about SPARK in articles, conferences, classes and blogs (in particular blog.adacore.com). Yannick previously worked on source code analyzers for PolySpace (now The MathWorks) and at Université Paris-Sud.
About Emmanuel Briot

Emmanuel Briot has been with AdaCore between 1998 and 2017. He has been involved in a variety of projects, in particular oriented towards graphical user interfaces, including GtkAda, GPS, XML/Ada, GnatTracker and our internal CRM. He holds an engineering degree from the Ecole Nationale des Telecommunications (Brest, France).
About Nicolas Roche

Nicolas Roche holds an engineering degree from Télécom Paris and a Master of Advanced Study in distributed system from Université Paris VI. He joined AdaCore as a Software Engineer in 2003. After being involved in the design and development of AdaCore supply-chain platform and transition of the platform to AWS cloud, he is now Principal Engineer for the the IT department