
Creating Your Own Ada/SPARK Coding Standard
by Michael Frank –
Introduction
Many of our customers ask if we have a "Coding Standard" that we can provide for writing code in Ada or SPARK. The answer has typically been: "We provide GNATcheck, which you can use to create your own." While this provides a lot of flexibility and control to the end user, sometimes a developer just wants to get things up and running as quickly as possible, and a generic coding standard is all that's needed. That's why AdaCore decided to help by creating a baseline coding standard that you can use as-is, or modify to fit your needs. For a web-based version of this document, see here. (There are also links to a PDF or EPUB version if you’re interested.)
First, we need to define what we mean by “coding standard”. Basically, it is a set of rules or guidelines that the programmer follows to ensure consistency throughout the code (things like naming conventions and code formatting) as well as good programming practices (enforcing short-circuit operators or preventing deeply nested generics). These rules are helpful in large projects with many engineers, because consistent formatting makes code easier to understand, and code structure rules have been developed over time to prevent previous issues from being ignored or forgotten.
A coding standard is a good thing, but if it’s just a document, then enforcing it becomes part of the code review process, taking time away from actually reviewing the design. Included in the GNAT Static Analysis Suite, AdaCore provides a tool called GNATcheck that defines many rules (and allows the user to define their own) that can be verified during a static analysis process on your code base. (I’m not going to get into the details of GNATcheck in this blog post – for more information on the tool you can look here.)
The coding standard we created is available via GitHub. It is a collection of ReStructured Text (RST) files that use the Sphinx utilities to create a document in your choice of formats (PDF, HTML, etc). Once generated, this document can serve as your official “Coding Standard” for your project. In addition, many of the standards detailed in the document specify the GNATcheck rules that can be used to enforce the standard. There is even a Python script in the tools folder (generate_rules_file.py) that will automatically parse the RST files and generate an input file for GNATcheck.
Coding Standard Contents Description
The coding standard has some beginning and ending text that is fairly boilerplate. There is a chapter introducing the concept of a Coding Standard, the guidelines chapter, and then chapters for references and licensing information.
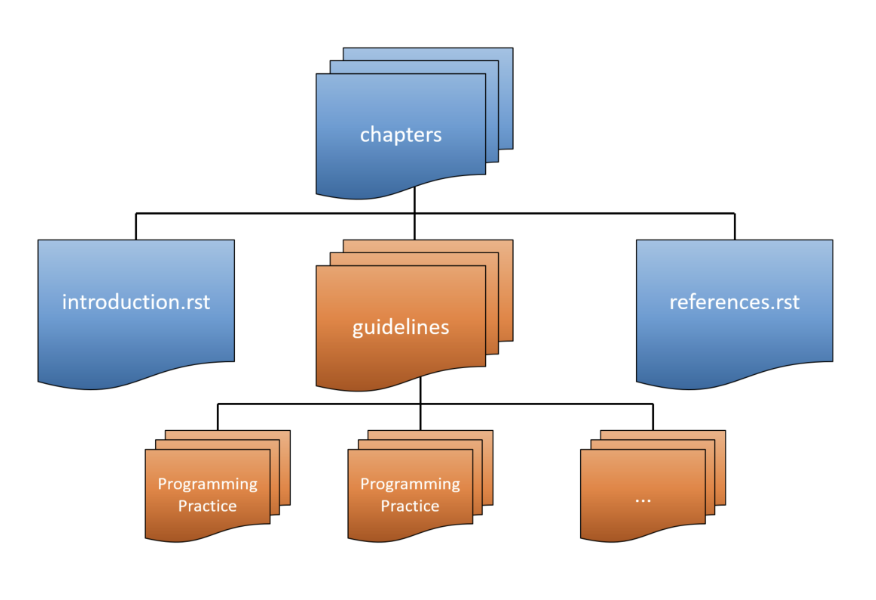
The real focus of the document is the “Guidelines” chapter. This chapter contains collections of programming practice topics, and each collection contains a list of standards to be followed. These general programming practices are categorized as follows:
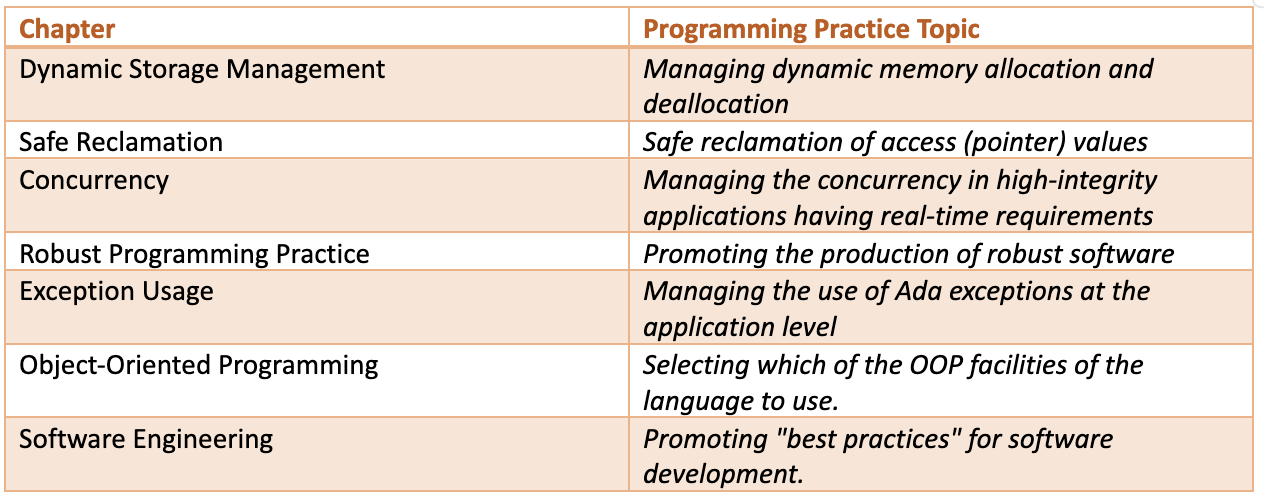
Each of these categories appears in its own chapter. Each chapter lists the goals of the category, a short description, and a list of the rules within the category.
Every standard within these categories follows the same format. The following subsections describe each part of a standard.
Title
The title contains a short description of the standard, and an identifier. The identifier currently begins with three characters that identify the collection, and a counter for the particular standard.
Level
The level indicates the risk involved in not following the standard. Coding standards can be requirement-based (such as raising exceptions) which can affect performance, for example, or just code formatting and naming conventions which only affect maintainability.
Category
Category contains two indicators of impact. Safety indicates if the standard pertains to safety-critical behaviors in the application, while Cyber indicates if the standard pertains to the ability to prevent malicious attacks on the application. These indicators are not mutually exclusive.
Goal
Goal contains a list of reasons why the standard is included in the document. The standard may be important because it increases maintainability or reliability, makes the code more reusable, improves performance, or addresses security concerns (or any combination of these issues).
Remediation
The coding standard needs to address the difficulty in repairing code that does not meet the specified standard. A High remediation value, for example, means that trying to change the code may take a significant effort.
Verification Effort
This category documents how the standard will be enforced. Ultimately, the more verification that can be done automatically, either through GNATcheck, or by adding “pragma Restrictions” to your code, the better. In the end, however, sometimes visual inspection will be the only way to verify the standard is met.
Reference
The reference section contains information about where the justification for the standard comes from. All references are documented in the coding standard – this is a good place to start looking for the rationale behind all these rules.
Description
This subsection contains a short description of the problem the rule is trying to solve. Typically, it describes the background of the problem, and why this particular rule is a good way to avoid it.
Applicable vulnerability within ISO TR 24772-2
This refers to the ISO Technical Report that documents many of the known vulnerabilities in Ada applications. Many of these rules address these vulnerabilities directly, so the reference is useful for background information.
Noncompliant Code Example
When appropriate, this section contains a snippet of Ada code that shows what code looks like when it does not conform to the rule.
Compliant Code Example
This section typically contains a modified version of the noncompliant code example, where it now conforms to the rule.
Notes
This section contains any additional information that may pertain to the justification of the rule, remediation possibilities, or verification methods.
Verifying the Coding Standard with GNATcheck
Many of the standards in this document contain the specific GNATcheck rule to verify the standard. To generate a rules file for GNATcheck, there is a python file (in the tools folder) called “generate_rules_file.py”. Running this script will generate the appropriate file to feed into GNATcheck for validating your source code. Then, to analyze your project, you simply run the command
gnatcheck -P<project> –show-rule -rules -from=<generated_file>
to generate a report.
Code Example With Output
The following code snippet looks fine - it might even pass code review. But our default Coding Standards would complain about a few things. Can you tell which lines would be flagged?
1 package Rpp03 is
2
3 package Noncompliant is
4 type Record_T is record
5 Field1 : Integer := 1;
6 Field2 : Boolean := False;
7 Field3 : Character := ' ';
8 end record;
9 type Array_T is array (Character) of Boolean;
10 Rec : Record_T := (Field1 => 1,
11 Field3 => '2',
12 others => <>);
13 Arr : Array_T := ('0' .. '9' => True,
14 others => False);
15 end Noncompliant;Running GNATcheck on this file would result in the following report (note that this is not the whole source file, nor is it the whole output).
rpp03.ads:4:12: type defines publicly accessible components
rpp03.ads:12:26: OTHERS choice in aggregate
rpp03.ads:14:25: OTHERS choice in aggregateThe first message indicates that record types should typically be private, to prevent the client from unnecessarily changing data. The second two messages indicate that using an others clause can mask problems either now or in the future.
Configuring Your Own Coding Standard
Many software projects have their own standards that they like to enforce, and a lot of them are represented in the list of predefined GNATcheck rules. (Note: you can also define your own rules, but that’s outside the scope of this blog post) There are rules for naming conventions (e.g. identifier_prefixes), enforcing coding styles (e.g. style_checks), or even preventing unwanted constructs (e.g. forbidden_pragmas). Adding these to the coding standard (or removing those that are currently in the default document) is easy!
Adding New Standards
Within the Guidelines for Safe and Secure Ada/SPARK part of the repository is a directory structure chapters/guidelines. For each guideline subsection, there is an RST file and a subfolder. To add a new standard, first go into the subfolder and create a new file for your standard. Feel free to use any of the other files as a template! Then, edit the subsection RST file to include your new standard file in the “.toctree” structure. That’s it – just rebuild the document and you’ve added your standard!
If your new standard is detectable using a GNATcheck rule, make sure you set the Verification Method field in your standard to indicate GNATcheck, and which rule it needs to verify. For example:
GNATcheck rule: :rule:`OTHERS_In_CASE_Statements`Adding a New Programming Practice Category
If you want to add a whole new collection of standards, the process is similar. Now, in the guidelines folder you need to add an RST file and subfolder and populate them appropriately. (Again, copy-and-paste is the best way to get started.) The extra step here is you need to modify the “.toctree” structure in the index.rst file (located in the Guidelines main directory) and add your new subsection.
Rebuilding the Document After Modification
Once you have customized the source files, you can build the document using the Sphinx utilities. Please refer to the README.md file in the repository for the most up-to-date build process.
Conclusion
Coding standards are great documents for any software project, because they (are supposed to) ensure that common guidelines are followed across multiple programmers. Having a well-documented standard that can be enforced by an automated tool is a bonus, because enforcement is no longer left up to code reviews – it can be done automatically by the programmer as the software is developed, meaning the programmer doesn’t have to go back and fix minor issues after a code review, and reviewers can focus on the important concepts of design and implementation instead of the trivial aspects of naming conventions and code formatting.
About Michael Frank

Michael has been programming in Ada for over 30 years. For most of his career he has been working on software testing tools for the embedded system market. He recently joined AdaCore to become a Mentor to the growing base of companies who are making the switch to Ada from other languages.