Finding Vulnerabilities using Advanced Fuzz testing and AFLplusplus v3.0
by Paul Butcher –
Some of you may recall an AdaCore blog post written in 2017 by Thales engineer Lionel Matias titled "Leveraging Ada Run-Time Checks with Fuzz Testing in AFL". This insightful post took us on a journey of discovery as Lionel demonstrated how Ada programs, compiled using GNAT Pro and an adapted assembler pass can be subjected to advanced fuzz testing. In order to achieve this Lionel demonstrated how instrumentation of the generated assembly code around jump and label instructions, could be subjected to grey-box (path aware) fuzz testing (using the original AFL v2.52b as the fuzz engine). Lionel explained how applying the comprehensive spectrum of Ada runtime checks, in conjunction with Ada's strong typing and contract based programming, enhanced the capabilities of fuzz testing beyond the abilities of other languages. Ada's advanced runtime checking, for exceptions like overflows, and the scrutiny of Ada's design by contract assertions allow corner case bugs to be found whilst also utilising fuzz testing to verify functional correctness.
The success of Thales' initial research work and the obvious potential for this technology (see the blog post for real world examples of the bugs Lionel found), coupled with the evolution of fuzzing tools from the wider community and the impressive bug finding success of AFL, lead to an ongoing AdaCore research and development campaign around advanced security hardening through vulnerability testing.
This blog post provides the reader with an update into the science of vulnerability testing and describes some of the projects AdaCore has undertaken around fuzzing technologies as we work towards an industrial grade fuzz testing solution for Ada applications.
In addition this blog post celebrates the recent inclusion of AdaCore's GCC plugin into the publicly available latest release of AFLplusplus (version 3.00c).
A Brief Introduction to Fuzzing
A modern-day definition of fuzzing would be a testing capability designed to automatically create and inject inputs into a software process under test, while monitoring and recording detected faults. When considered, as part of a software development strategy, fuzzing is widely regarded as ‘negative testing’ and tends to fall under the remit of ‘software robustness’. More recently, however, it has been widely associated with ‘cyber-security’ and proven to be a suitable mechanism for finding code vulnerabilities that could otherwise lead to malicious exploitation. In this context, it is often known as ‘vulnerability testing’. In addition the term 'Refutation Testing', used in the context of aerospace security airworthiness and used to describe the act of 'refuting that our system is not secure', can also be used to describe fuzz testing.
Fuzzing, as a robustness strategy, has evolved exponentially since its initial inception back in the 1980s. Although the goal of fuzzing is always the same, tool development has forked in many directions such that different fuzzing tools use different test strategies and vary significantly in sophistication and complexity. Simplistic ‘black box’ fuzzers rely on brute force and speed of test case generation and execution. Whilst others instrument the code under test before, or during, compilation to allow the fuzzing engine to understand execution flow around decision points and to help guide the mutation engine onto diverging paths.
One of the main features of fuzz testing is rapid and automated test case generation and, as is the case within AFLplusplus, this is often achieved by a series of mutation phases over a starting corpus of test case files. The mutations tend to be 'non-structure aware' and instead alter the test case at the binary level by performing bit flips. That being said AFLplusplus does support an impressive custom mutation algorithm API that we will talk about later. Mutated test cases are then injected into the system under test while the fuzzer simultaneously monitors the application to detect a hung process or core dump. Test cases that resulted in a software fault are then placed in a separate directory for later manual scrutiny. This approach provides flexibility as the engine doesn't need to understand the format of the input data.
Instrumentation Guided Genetic Algorithms
AFLplusplus understands, by using test instrumentation applied during code compilation, when a test case has found a new path (increased coverage) and places that test case onto a queue for further mutation, injection and analysis. The fuzzing driver sets up a small shared memory area for the tested program to store execution path signatures. This structure is a basic array of counters incremented (or set) as execution reaches instrumentation points. Each instrumentation point is assigned, at compile time, a pseudo-random identifier. The array element to be incremented at run time is determined by hashing ordered pairs of identifiers of previous and current instrumentation points, to count the traversal of edges.
Though the driver can spawn (fork and exec) a new test process for each execution, instrumentation of the test program introduces a fork server mode that maps the shared memory and forks a new test process when requested by the driver. This avoids the overhead of exec and of running global constructors.
The aim of the instrumentation is to focus on non-intrusive manipulation; the fuzzer does not rely on complex code analysis or other forms of constraint solving. This form of 'path awareness' fuzzing, using an instrumentation-guided genetic algorithm, focuses the mutations on the test cases that discover path divergence and allows the testing to explore deeper into the control flow.
Figure 1 presents a basic representation of a Grey Box Fuzz Testing Architecture.

Mutation Strategies - "One size doesn't fit all"
Mutators applied to test inputs can be deterministic or nondeterministic. This flexibility encompasses changes suitable for both text and binary file formats. Mutators involve flipping single or multiple contiguous bits, arithmetic add and subtract at various word widths and endiannesses; overwrites, inserts and deletes. Deterministic mutators iterate over all bits or bytes of an input file, generating one or multiple new potential input tests at each iteration point. Nondeterministic approaches may perform multiple random mutations at random points and with random operands. In addition, chunks from another test may be spliced into the current before another round of random mutations. Some arithmetic mutators use a selection of “interesting” values, while string mutators use blocks of constant values. These are copies of chunks from elsewhere in the test input, fuzzer-identified tokens, and user-supplied keywords.

In figure 2 we can see a basic example of a deterministic mutation strategy and a non-deterministic strategy. The deterministic strategy involves flipping each bit within the test case to produce a new test case whilst the non-deterministic approach shows random sequences of bits being swapped around whilst other sequences are flipped at the same time. However in most cases the mutation engines will actually utilise pseudo-random number generators which are seeded to ensure patterns are repeatable.
An Enhanced GCC Instrumentation Approach
American Fuzzy Lop (AFL) was a revolutionary game changer for fuzzing technologies. For many security engineers and researchers it quickly became the de facto standard for how to implement a generic grey box fuzzing engine. AFL paved the way for the genetic algorithm approach to test data mutation through execution path awareness and without compromise of test execution frame rates. Coupled with an easy to understand interface and high configurability and the fact that AFL has always been 'free software' (in that users have the freedom to run, copy, distribute, study, change and improve the software), lead to the discovery and patching of multiple vulnerabilities within released, and widely used, commercial software applications. AFL can also support full black box testing by utilising modern emulator technology which allows vulnerabilities to be discovered on binary executables when the source code and / or build environment is not available.
Although AFL v2.52b offered a post-processor to instrument assembly output from the compiler, it was target architecture specific, and introduced significant run-time overhead. AFL v2.52b did offer up a pre-existing plugin for LLVM with much lower-overhead instrumentation, but GCC users had to tolerate higher instrumentation overheads. In order to ensure that GCC compiled applications could benefit from a low-overhead and optimizable AFL instrumentation AdaCore took inspiration from an existing plugin, originally developed for instrumenting programs written in 'C', to create a new feature rich and modern GCC plugin for the AFL fuzzing engine.
Building the program with instrumentation for AFL amounts to inserting an additional stage of processing whereby the compiler's assembly code output is modified, before running the actual assembler. This additional build stage introduces global variables, a fork-server and edge counting infrastructure in the translation unit that defines the main function and calls to an edge counting function after labels and conditional branches. In order to not disturb the normal execution of the program, each such call must preserve all registers modified by the edge counter, and by the call sequence, e.g. to pass the identifier of the current instrumentation point as an argument to the edge counter. The edge counter loads the previous instrumentation point identifier from a global variable and updates it, in addition to incrementing the signature array element associated with the edge between them.
Integrating the additional instrumentation stages into the compiler enables several improvements, as demonstrated by the pre-existing plugin for LLVM, and a newly introduced one for GCC. Besides portability to multiple target architectures, this move enables the instrumentation to be integrated more smoothly within the code stream. For example, while the assembler post-processor, with its limited knowledge, has to conservatively assume several registers need to be preserved across the edge counter calls, the compiler can take the calls into account when performing register allocation or, even better, avoid the call overhead entirely and perform the edge counting inline.
Using compiler infrastructure also makes it easier to use a thread-local variable to hold the previous instrumentation point identifier, so that programs with multiple threads do not confuse the fuzzer with cross-thread edges. The sooner in the compiler pipeline instrumentation is introduced, the more closely it will resemble the source code structure, and the more opportunities to optimize the instrumentation there will be. Conversely, the later it is introduced, the more closely it will resemble the executable code blocks after optimization, so duplicated blocks, e.g. resulting from loop unrolling, get different identifiers, and merged blocks, e.g. after jump threading, may end up with fewer instrumentation points.
AFLplusplus
AFLplusplus takes up the mantle from where AFL v2.52b left off adding various enhancements to the capability whilst also offering up a highly customisable, tool chain-able and extendable approach through it's modular architecture.
One particular feature of AFLplusplus of interest is the ability to add custom mutator algorithms which can either extend, sanitise or completely replace the AFL internal mutation engine.
This, along with other features and a strong interest in industry lead by Thales, guided AdaCore towards ensuring our GCC plugin was compatible with AFLplusplus and ensuring that new features, developed into the existing AFLplusplus GCC plugin, were reimplemented in the AdaCore developed plugin.
This work has now been completed and in partnership with Thales and with support from the AFLplusplus maintainer team AdaCore have since upstreamed the work into the publicly available AFLplusplus repository.
Or to quote the AFLplusplus public github repo:

Fuzz Testing Ada Programs
Programming languages come with a variety of runtime libraries which are responsible for abstracting away fundamental architecture required to execute program instructions. By design each runtime is matched to the predicted role of the programming language and Ada, which is aimed at safety and security systems, is no exception. Runtimes, like the Ada runtime, that support advanced constraint checking are particularly well suited to fuzz testing. Languages, like 'C', with runtimes that allow some constraints to go unchecked are less well suited.
The following examples explain this better:
C program that receives a password as a command line argument and displays secret information if the password = "A*^%bd0eK":
#include <string.h>
#include <stdio.h>
void Expose_Secrets_On_Correct_Password (char *Password)
{
int Privileged = 0;
char Password_Buff[10];
memcpy (Password_Buff, Password, strlen(Password));
if (strcmp (Password_Buff, "A*^%bd0eK") == 0)
{
Privileged = 1;
}
if (Privileged != 0)
{
printf ("Shhhh... the answer to life the universe and everything is 42!\n");
} else {
printf ("Pah. There is no getting passed this system's hardened security layer...\n");
}
}
int main(int argc, char **argv)
{
Expose_Secrets_On_Correct_Password(argv[1]);
return 0;
}Ada equivalent version (disclaimer: implemented to closely represent the C code above and I'm not in anyway advocating that this is the correct way to write Ada - because it clearly isn't!)
with Ada.Text_IO; use Ada.Text_IO;
with Ada.Command_Line;
pragma Warnings (Off);
procedure API_Fuzzing_Example is
procedure Expose_Secrets_On_Correct_Password (Password : access String);
procedure Expose_Secrets_On_Correct_Password (Password : access String) is
Privileged : Integer := 0;
Password_Buff : String (1 .. 9);
begin
Password_Buff := Password.all;
if Password_Buff = "A*^%bd0eK" then
Privileged := 1;
end if;
if Privileged /= 0 then
Put_Line ("Shhhh... the answer to life the universe and everything is 42");
else
Put_Line ("Pah. There is no getting passed this system's hardened security layer...");
end if;
end Expose_Secrets_On_Correct_Password;
Entered_Password : aliased String := Ada.Command_Line.Argument (1);
begin
Expose_Secrets_On_Correct_Password (Password => Entered_Password'Access);
end API_Fuzzing_Example;Both code examples above contain an array overflow bug. In particular the assignment to variable 'Password_Buffer' will overflow if the command line argument contains a String greater than 9 characters.
For the examples above let's assume that the encompassing applications have system security requirements around the protection of the identified security asset: "the answer to life the universe and everything".
Let's now consider what happens when both of these programs execute with the following command line arguments:
1. "A*^%bd0eK"
This is the correct password. Both programs correctly expose the security asset by displaying: "Shhhh... the answer to life the universe and everything is 42!"
2. "123456789"
This is an incorrect password. Both programs correctly protect the security asset by displaying: "Pah. There is no getting passed this system's hardened security layer..."
3. "Password"
This is an incorrect password. The Ada runtime raises a constraint error on line 14 "Password_Buff := Password.all;" stating "length check failed". The exception is unhandled so the program terminates - the security asset is protected.
The C program displays: "Pah. There is no getting passed this system's hardened security layer..." - the security asset is also protected.
4. "A*^%bd0eKKKK"
This is an incorrect password. The Ada runtime raises a constraint error on line 14 "Password_Buff := Password.all;" stating "length check failed". The exception is unhandled so the program terminates - the security asset is protected.
The C program displays: "Shhhh... the answer to life the universe and everything is 42!". The security asset is now exposed and can be exploited by the attacker.
But why?
You will have likely spotted the reason the C program failed to protect the asset which is obviously due to the memcpy overflow writing data into the neighbouring 'int' variable 'Privileged'. This type of stack overflow exploitation is a widely recognised security issue within C programs and various counter measures exist to prevent this type of vulnerability. For example random stack memory allocation can help ensure the overflow leads to a core dump rather than continuing to execute with corrupted state.
The issue is exasperated when you consider that fuzz testing the C program may or may not reveal the bug. The overflow error could eventually cause a segmentation fault however, this is not guaranteed. Fuzz testing the Ada program however would quickly identify the problem and allow the developer to fix the bug with some basic defensive programming and therefore remove the vulnerability altogether.
Fuzzing into the Future
Within the UK AdaCore is actively researching and developing a fuzz testing solution for Ada based software as part of the “High-Integrity, Complex, Large, Software and Electronic Systems” (HICLASS) Aerospace Technology Institute (ATI) supported research and development programme. HICLASS was created to enable the delivery of the most complex, software-intensive, safe and cyber-secure systems in the world and is best described in an earlier AdaCore blog post titled "AdaCore for HICLASS - Enabling the Development of Complex and Secure Aerospace Systems".
Stage one of this work involved the development of an Ada library to abstract away the complexity involved in fuzz testing Ada programs at the unit level. Unit level fuzz testing involves considering the test case files as in-memory representations of identified test data. The test data is any software variables the test engineer would like the fuzzer to drive and this is typically made up of 'in mode' parameters for the function under test, global state, stub return values and even private state manipulated through test injection points or memory overlays. Once the test data has been identified a series of generic packages are instantiated with the Ada types associated with the test data. These packages are responsible for marshalling and unmarshalling the starting corpus and mutated test cases between binary files and Ada variables; we call this collection of test data information an "AFL Map". A simple test harness is then constructed which receives the test case from the fuzzer via a String file path within a command line parameter. The unmarshalled data is then used to setup and execute the test. In addition a top level exception handler is placed in the test harness to capture unexpected exceptions raised by the runtime, these are converted into core dumps to signal a fault to the fuzzer.
Figure 3 shows a high level overview of the architecture of unit level fuzz testing for Ada.

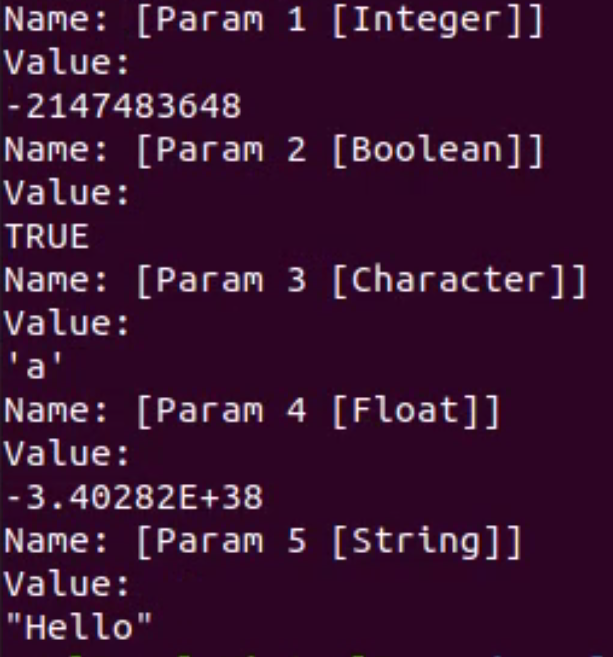
In addition, this work also involved researching and developing a prototype 'Starting Corpus Generator' to create the initial set of test cases that the fuzzer will mutate and a 'Test Case Printer' to convert binary test cases into a human readable syntax. Figure 4 below shows the content of a binary test case created using an AFL Map made up of test case data with the types: Integer, Boolean, Character, Float and String and the human readable version created using the Test Case Printer.

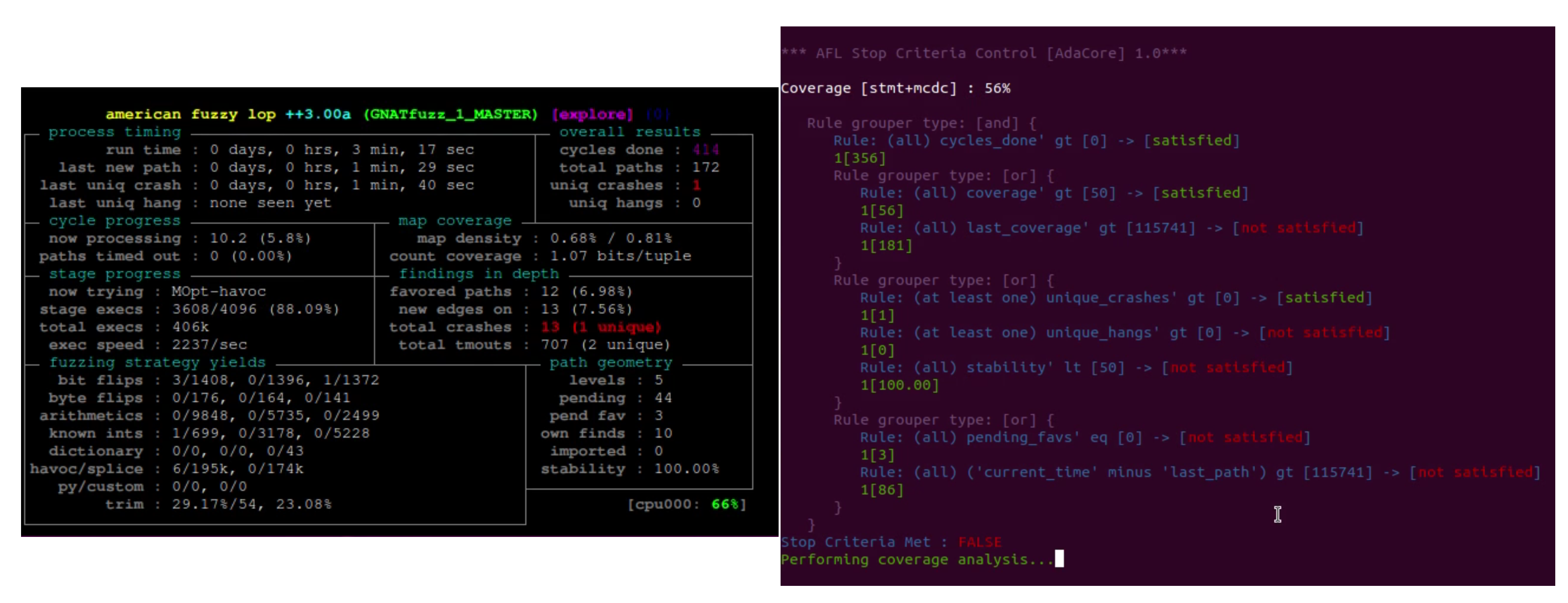
Stage two of this work required the construction of a separate Ada application to automate the building and executing of Ada fuzz tests. In addition this application allows the test engineer to build up a set of stop criteria rules that, when satisfied, will terminate the fuzzing session. The rules are based around the exposed state of AFLplusplus which the fuzzing engine broadcasts every thirty seconds. This tool also features an incorporated coverage capability through GNATcoverage allowing for dynamic full MCDC coverage analysis that can also be included within the stop criteria rules. Finally this tool allows for additional AFLplusplus companion applications to easily be utilised by Ada fuzzing sessions - including starting corpus minimisation and utilising maximum available processor cores to run multiple afl-fuzz instances simultaneously.
Figure 5 below shows this tool in action with an active AFLplusplus fuzzing session.
Stage 3 involved the building of a fuzzer benchmark testing suite used internally to perform comparisons between versions of the capability as new prototype enhancements are developed.
Stage 4 is where we research and develop a prototype structure aware custom mutation engine for Ada fuzzing sessions. This application is being developed as a standalone dynamic library that implements the AFLplusplus custom mutation API. The library can then be registered with an active AFLplusplus session, to unmarshall the received byte array representations of the test case data into their associated Ada types before being sent to type specific custom mutation packages for manipulation.
Stage 5 is looking into random automated test case generation. This capability will form the basis of the starting corpus of test cases by automatically generating wide ranging sets of test case data. In addition it will be utilised by the custom mutation library to mutate the data whilst ensuring the data remains correctly constrained.
Stage 6 involves further automation in the form of automated test harness creation and test data identification.
Final Note...
Fuzz testing is seen by AdaCore as a key tool in the software development process for asset protection within security related and security critical applications and continued effort will be applied to ensure the capability matches the needs of our customers. In addition when combining Fuzzing with other security based tools such as static code analysers like CodePeer and formal verification tools like SPARK Pro, and particularly when the tools come with extensive documentation showing mitigation against the top CWEs, the result can be a cyber-secure software development environment fit for the modern cyber-warfare battle ground.
To conclude: the future may be fuzzy but we're ok with that! ;-)
About Paul Butcher

Paul is the UK Programme Manager, Head of Dynamic Analysis for AdaCore, and the Lead Engineer for GNATfuzz. He has over 25 years of experience in developing and verifying embedded safety-critical real-time systems. Before joining AdaCore, Paul was a consultant engineer, working for UK aerospace companies such as Leonardo Helicopters, BAE Systems, Thales UK, and QinetiQ. Before becoming a consultant, Paul worked as a Software Developer and Safety Engineer for the Typhoon platform, safety-critical automated train driving software, military UAVs, the Tactical Processor for the Wildcat platform, and mission planning systems for Typoon, EH101, and Wildcat. Paul graduated from the University of Portsmouth with a Bachelor’s Degree with Honours in Computing and a Higher National Diploma in Software Engineering.