
Leveraging Ada Run-Time Checks with Fuzz Testing in AFL
by Lionel Matias –
Fuzzing is a very popular bug finding method. The concept, very simply, is to continuously inject random (garbage) data as input of a software component, and wait for it to crash. Google's Project Zero team made it one of their major vulnerability-finding tools (at Google scale). It is very efficient at robust-testing file format parsers, antivirus software, internet browsers, javascript interpreters, font face libraries, system calls, file systems, databases, web servers, DNS servers... When Heartbleed came out, people found out that it was, indeed, easy to find. Google even launched a free service to fuzz at scale widely used open-source libraries, and Microsoft created Project Springfield, a commercial service to fuzz your application (at scale also, in the cloud).
Writing robustness tests can be tedious, and we - as developers - are usually bad at it. But when your application is on an open network, or just user-facing, or you have thousands of appliance in the wild, that might face problems (disk, network, cosmic rays :-)) that you won't see in your test lab, you might want to double-, triple-check that your parsers, deserializers, decoders are as robust as possible...
In my experience, fuzzing causes so many unexpected crashes in so many software parts, that it's not unusual to spend more time doing crash triage than preparing a fuzzing session. It is a great verification tool to complement structured testing, static analysis and code review.
Ada is pretty interesting for fuzzing, since all the runtime checks (the ones your compiler couldn't enforce statically) and all the defensive code you've added (through pre-/post-conditions, asserts, ...) can be leveraged as fuzzing targets.
Here's a recipe to use American Fuzzy Lop on your Ada code.
American Fuzzy Lop
AFL is a fuzzer from Michał Zalewski (lcamtuf), from the Google security team. It has an impressive trophy case of bugs and vulnerabilities found in dozens of open-source libraries or tools.
You can even see for yourself how efficient guided fuzzing is in the now classic 'pulling jpegs out of thin air' demonstration on the lcamtuf blog.
I invite you to read the technical description of the tool to get a precise idea of the innards of AFL.
Installation instructions are covered in the Quick Start Guide, and they can be summed as:
- Get the latest source
- Build it (make)
- Make your program ready for fuzzing (here you have to work a bit)
- Start fuzzing...
There are two main parts of the tool:
- afl-clang/afl-gcc to instrument your binary
- and afl-fuzz that runs your binary and uses the instrumentation to guide the fuzzing session.
Instrumentation
afl-clang / afl-gcc compiles your code and adds a simple instrumentation around branch instructions. The instrumentation is similar to gcov or profiling instrumentation but it targets basic blocks. In the clang world, afl-clang-fast uses a plug-in to add the instrumentation cleanly (the compiler knows about all basic blocks, and it's very easy to add some code at the start of a basic block in clang). In the gcc world the tool only provides a hacky solution.
The way it works is that instead of calling your GCC of predilection, you call afl-gcc. afl-gcc will then call your GCC to output the assembly code generated from your code. To simplify, afl-gcc patches every jump instruction and every label (jump destination) to append an instrumentation block. It then calls your assembler to finish the compilation job.
Since it is a pass on assembly code generated from GCC it can be used to fuzz Ada code compiled with GNAT (since GNAT is based on GCC). In the gprbuild world this means calling gprbuild with the --compiler-subst=lang,tool option (see gprbuild manual).
Note : afl-gcc will override compilation options to force -O3 -funroll-loops. The reason behind this is that the authors of AFL noticed that those optimization options helped with the coverage instrumentation (unrolling loops will add new 'jump' instructions).
With some codebases there can appear a problem with the 'rep ret' instruction. For obscure reasons gcc sometimes insert a 'rep ret' instruction instead of a ‘ret’ (return) instruction. Some info on the gcc mailing list archives and in more detail if you dare on a dedicated website call repzret.org.
When AFL inserts its instrumentation code, the 'rep ret' instruction is not correct anymore ('as' complains). Since 'rep ret' is exactly the same instruction (except a bit slower on some AMD arch) as ‘ret’, you can add a step in afl-as (the assembly patching module) to patch the (already patched) assembly code: add the following code at line 269 in afl-as.c (on 2.51b or 2.52b versions):
if (!strncmp(line, "\trep ret", 8)) {
SAYF("[LMA patch] afl-as : replace 'rep ret' with (only) 'ret'\n");
fputs("\tret\n", outf);
continue;
}... and then recompile AFL. It then works fine, and prints a specific message whenever it encounters the problematic case. I didn't need this workaround for the example programs I chose for this post (you probably won't need it), but it can happen, so here you go...
Though a bit hacky, going through assembly and sed-patching it seems the only way to do this on gcc, for now. It's obviously not available on any other arch (power, arm) as such, as afl-as inserts an x86-specifc payload. Someone wrote a gcc plug-in once and it would need some love to be ported to a gcc-6 (recent GNAT) or -8 series (future GNAT). The plug-in approach would also allow to do in-process fuzzing, speed-up the fuzzing process, and ease the fuzzing of programs with a large initialization/set-up time.
When you don't have the source code or changing your build chain would be too hard, the afl-fuzz manual mentions a Qemu-based option. I haven't tried it though.
The test-case generator
It takes a bunch of valid inputs to your application, and implements a wide variety of random mutations, runs your application with them and then uses the inserted instrumentation to guide itself to new code paths and avoid staying too much on paths that already crash.
AFL looks for crashes. It is expecting a call to abort() (SIGABRT).
Its job is to try and crash your software, its search target is "a new unique crash".
It's not very common to get a core dump (SIGSEGV/SIGABRT) in Ada with GNAT, even following an uncaught top-level exception. You'll have to help the fuzzer and provoke core dumps on errors you want to catch. A top-level exception by itself won't do it. In the GNAT world you can dump core using the Core_Dump procedure in the GNAT-specific package GNAT.Exception_Actions. What I usually do is let all exceptions bubble up to a top-level exception handler and filter by name, and only crash/abort on the exceptions I'm interested in. And if the bug you're trying to find with fuzzing doesn't crash your application, make it a crashing bug.
With all that said, let’s find some open-source libraries to fuzz.
Fuzzing Zip-Ada
Zip-Ada is a nice pure-Ada library to work with zip archives. It can open, extract, compress, decompress most of the possible kinds of zip files. It even has implemented recently LZMA compression. It's 100% Ada, portable, quite readable and simple to use (drop the source, use the gpr file, look up the examples and you're set). And it's quite efficient (say my own informal benchmarks). Anyway it's a cool project to contribute to but I'm no compression wizard. Instead, let's try and fuzz it.
Since it's a library that can be given arbitrary files, maybe of dubious source, it needs to be robust.
I got the source from sourceforge of version 52 (or if you prefer, on github), uncompressed it and found the gprbuild file. Conveniently Zip-Ada comes with a debug mode that enables all possible runtime checks from GNAT, including -gnatVa, -gnato. The zipada.gpr file also references a 'pragma file' (through -gnatec=debug.pra) that contains a 'pragma Initialize_Scalars;' directive so everything is OK on the build side.
Then we need a very simple test program that takes a file name as a command-line argument, then drives the library from there. File parsers are the juiciest targets, so let's read and parse a file: we'll open and extract a zip file. For a first program what we're looking for is procedure Extract in the Unzip package:
-- Extract all files from an archive (from)
procedure Extract (From : String;
Options : Option_set := No_Option;
Password : String := "";
File_System_Routines : FS_Routines_Type := Null_Routines)Just give it a file name and it will (try to) parse it as an archive and extract all the files from the archive.
We also need to give AFL what it needs (abort() / core dump) so let's add a top-level exception block that will do that, unconditionally (at first) on any exception.
The example program looks like:
with UnZip; use UnZip;
with Ada.Command_Line;
with GNAT.Exception_Actions;
with Ada.Exceptions;
with Ada.Text_IO; use Ada.Text_IO;
procedure Test_Extract is
begin
Extract (From => Ada.Command_Line.Argument (1),
Options => (Test_Only => True, others => False),
Password => "",
File_System_Routines => Null_routines);
exception
when Occurence : others =>
Put_Line ("exception occured [" & Ada.Exceptions.Exception_Name (Occurence)
& "] [" & Ada.Exceptions.Exception_Message (Occurence)
& "] [" & Ada.Exceptions.Exception_Information (Occurence) & "]");
GNAT.Exception_Actions.Core_Dump (Occurence);
end Test_Extract;And to have it compile, we add it to the list of main programs in the zipada.gpr file.
Then let's build:
gprbuild --compiler-subst=Ada,/home/lionel/afl/afl-2.51b/afl-gcc -p -P zipada.gpr -Xmode=debug
We get a classic gprbuild display, with some additional lines:
... afl-gcc -c -gnat05 -O2 -gnatp -gnatn -funroll-loops -fpeel-loops -funswitch-loops -ftracer -fweb -frename-registers -fpredictive-commoning -fgcse-after-reload -ftree-vectorize -fipa-cp-clone -ffunction-sections -gnatec../za_elim.pra zipada.adb afl-cc 2.51b by <lcamtuf@google.com> afl-as 2.51b by <lcamtuf@google.com> [+] Instrumented 434 locations (64-bit, non-hardened mode, ratio 100%). afl-gcc -c -gnat05 -O2 -gnatp -gnatn -funroll-loops -fpeel-loops -funswitch-loops -ftracer -fweb -frename-registers -fpredictive-commoning -fgcse-after-reload -ftree-vectorize -fipa-cp-clone -ffunction-sections -gnatec../za_elim.pra comp_zip.adb afl-cc 2.51b by <lcamtuf@google.com> afl-as 2.51b by <lcamtuf@google.com> [+] Instrumented 45 locations (64-bit, non-hardened mode, ratio 100%). ...
The 2 additional afl-gcc and afl-as steps show up along with a counter of instrumented locations in the assembly code for each unit. So, some instrumentation was inserted.
Fuzzers are bad with checksums (http://moyix.blogspot.fr/2016/07/fuzzing-with-afl-is-an-art.html is an interesting dive into what can block afl-fuzz and what can be done, and John Regehr had a blog post on what AFL is bad at). For example, there’s no way for a fuzzing tool to go through a checksum test: it would need to generate only test cases that have a matching checksum. So, to make sure we get somewhere, I removed all checksum tests. There was one for zip CRC. Another one for zip passwords, for similar reasons. After I commented out those tests, I recompiled the test program.
Then we’ll need to build a fuzzing environnement:
mkdir fuzzing-session mkdir fuzzing-session/input mkdir fuzzing-session/output
We also need to bootstrap the fuzzer with an initial corpus that doesn't crash. If there's a test suite, put the correct files in input/.
Then afl-fuzz can (finally) be launched:
AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=ON \ /home/lionel/afl/afl-2.51b/afl-fuzz -m 1024 -i input -o output ../test_extract @@ -i dir - input directory with test cases -o dir - output directory for fuzzer findings -m megs - memory limit for child process (50 MB) @@ to tell afl to put the input file as a command line argument. By default afl will write to the program's stdin.
The AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=ON prelude is to silence a warning from afl-fuzz about how your system handles core dumps (see the man page for core). For afl-fuzz it's a problem because whatever is done to handle core dumps on your system might take some time and afl-fuzz will think the program timed out (although it crashed). For you it can also be a problem : It’s possible (see : some linux distros) that it’d instruct your system to do something (send a UI notification, fill your /var/log/messages, send a crash report e-mail to your sysadmin, …) with core dumps automatically (and you might not care). Maybe check first with your sysadmin… If you’re root on your machine, follow afl-fuzz’s advice and change your /proc/sys/kernel/core_pattern to something sensitive.
Let’s go:

In less than 2 minutes, afl-fuzz finds several crashes. While it says they’re “unique”, they in fact trigger the same 2 or 3 exceptions. After 3 hours, it “converges” to a list of crashes, and letting it run for 3 days doesn’t bring another one.
It got a string of CONSTRAINT_ERRORs:
CONSTRAINT_ERROR : unzip.adb:269 range check failed
CONSTRAINT_ERROR : zip.adb:535 range check failed
CONSTRAINT_ERROR : zip.adb:561 range check failed
CONSTRAINT_ERROR : zip-headers.adb:240 range check failed
CONSTRAINT_ERROR : unzip-decompress.adb:650 range check failed
CONSTRAINT_ERROR : unzip-decompress.adb:712 index check failed
CONSTRAINT_ERROR : unzip-decompress.adb:1384 access check failed
CONSTRAINT_ERROR : unzip-decompress.adb:1431 access check failed
CONSTRAINT_ERROR : unzip-decompress.adb:1648 access check failed
I sent those and the reproducers to Gautier de Montmollin (Zip-Ada's maintainer). He corrected those quickly (revisions 587 up to 599). Most of those errors now are raised as Zip-Ada-specific exceptions. He also decided to rationalize the list of raised exceptions that could (for legitimate reasons) be raised from the Zip-Ada decoding code.
It also got some ADA.IO_EXCEPTIONS.END_ERROR:
ADA.IO_EXCEPTIONS.END_ERROR : zip.adb:894
ADA.IO_EXCEPTIONS.END_ERROR : s-ststop.adb:284 instantiated at s-ststop.adb:402
I redid another fuzzing session after all the corrections and improvements confirming the list of exceptions.
This wasn’t a lot of work (for me), mostly using the cycles on my machine that I didn’t use, and I got a nice thanks for contributing :-).
Fuzzing AdaYaml
AdaYaml is a library to parse YAML files in Ada.
Let’s start by cloning the github repository (the one before all the corrections). For those not familiar to git (here's a tutorial) :
git clone https://github.com/yaml/AdaYaml.git git checkout 5616697b12696fd3dcb1fc01a453a592a125d6dd
Then the source code of the version I tested should be in the AdaYaml folder.
If you don't want anything to do with git, there's a feature on github to download a Zip archive of a version of a repository.

AdaYaml will ask for a bit more work to fuzz: we need to create a simple example program, then add some compilation options to the GPR files (-gnatVa, -gnato) and to add a pragma configuration file to set pragma Initialize_Scalars. This last option, combined with -gnatVa helps surface accesses to uninitialized variables (if you don't know the option : https://gcc.gnu.org/onlinedocs/gcc-4.6.3/gnat_rm/Pragma-Initialize_005fScalars.html and http://www.adacore.com/uploads/technical-papers/rtchecks.pdf). All those options to make sure we catch the most problems possible with runtime checks.
The example program looks like:
with Utils;
with Ada.Text_IO;
with Ada.Command_Line;
with GNAT.Exception_Actions;
with Ada.Exceptions;
with Yaml.Dom;
with Yaml.Dom.Vectors;
with Yaml.Dom.Loading;
with Yaml.Dom.Dumping;
with Yaml.Events.Queue;
procedure Yaml_Test
is
S : constant String := Utils.File_Content (Ada.Command_Line.Argument (1));
begin
Ada.Text_IO.Put_Line (S);
declare
V : constant Yaml.Dom.Vectors.Vector := Yaml.Dom.Loading.From_String (S);
E : constant Yaml.Events.Queue.Reference :=
Yaml.Dom.Dumping.To_Event_Queue (V);
pragma Unreferenced (E);
begin
null;
end;
exception
when Occurence : others =>
Ada.Text_IO.Put_Line (Ada.Exceptions.Exception_Information (Occurence));
GNAT.Exception_Actions.Core_Dump (Occurence);
end Yaml_Test;The program just reads a file and parses it, transforms it into a vector of DOM objects, then transforms those back to a list of events (see API docs).
The YAML reference spec may help explain a bit what's going on here.
Using the following diagram, and for those well-versed in YAML:
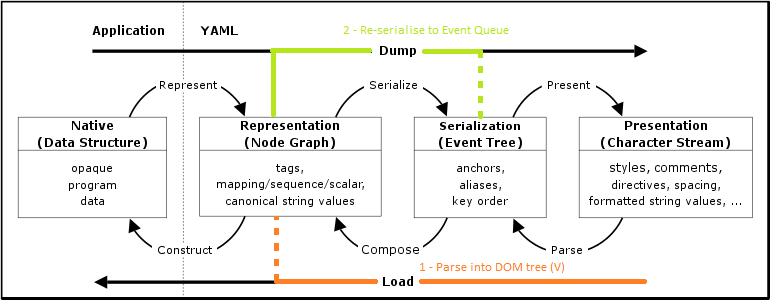
- the V variable (of our test program) is a "Representation" generated via the Parse -> Compose path
- the E variable is an "Event Tree" generated from V via "Serialize" (so, going back down to a lower-level representation from the DOM tree).
For this specific fuzzing test, the idea is not to stop at the first stage of parsing but also to go a bit through the data that was decoded, and do something with it (here we stop short of a round-trip to text, we just go back to an Event Tree).
Sometimes a parser faced with incoherent input will keep on going (fail silently) and won't fill (initialize) some fields.
The GPR files to patch are yaml.gpr and the parser_tools.gpr subproject.
The first fuzzing session triggers “expected” exceptions from the parser:
YAML.PARSER_ERROR
YAML.COMPOSER_ERROR
LEXER.LEXER_ERROR
YAML.STREAM_ERROR(as it turns out, this one is also unexpected... more on this one later)
Which should happen with malformed input.
So to get unexpected crashes and only those, let’s filter them in the top-level exception handler.
exception
when Occurence : others =>
declare
N : constant String := Ada.Exceptions.Exception_Name (Occurence);
begin
Ada.Text_IO.Put_Line (Ada.Exceptions.Exception_Information (Occurence));
if N = "YAML.PARSER_ERROR"
or else N = "LEXER.LEXER_ERROR"
or else N = "YAML.STREAM_ERROR"
or else N = "YAML.COMPOSER_ERROR"
then
null;
else
GNAT.Exception_Actions.Core_Dump (Occurence);
end if;
end Yaml_Test;Then, I recompiled, used some YAML example files as a startup corpus, and started fuzzing.

After 4 minutes 30 seconds, the first crashes appeared.
I let it run for hours, then a day and found a list of issues. I sent all of those and the reproducers to Felix Krause (maintainer of the AdaYaml project).
He was quick to answer and analyse all the exceptions. Here are his comments:
ADA.STRINGS.UTF_ENCODING.ENCODING_ERROR : bad input at Item (1)
I guess this happens when you use a unicode escape sequence that codifies a code point beyond the unicode range (0 .. 0x10ffff). Definitely an error and should raise a Lexer_Error instead.
… and he created issue https://github.com/yaml/AdaYaml/issues/4
CONSTRAINT_ERROR : text.adb:203 invalid data
This hints to a serious error in my custom string allocator that can lead to memory corruption. I have to investigate to be able to tell what goes wrong here.
… and then he found the problem: https://github.com/yaml/AdaYaml/issues/5
CONSTRAINT_ERROR : Yaml.Dom.Mapping_Data.Node_Maps.Insert: attempt to insert key already in map
This happens when you try to parse a YAML mapping that has two identical keys (this is conformant to the standard which disallows that). However, the error should be catched and a Compose_Error should be raised instead.
… and he opened https://github.com/yaml/AdaYaml/issues/3
CONSTRAINT_ERROR : yaml-lexer-evaluation.adb:283 overflow check failed
CONSTRAINT_ERROR : yaml-lexer-evaluation.adb:286 overflow check failed
CONSTRAINT_ERROR : yaml-lexer-evaluation.adb:289 overflow check failed
This is, thankfully, an obvious error: Hex escape sequence in the input may have up to eight nibbles, so they represent a value range of 0 .. 2**32 - 1. I use, however, a Natural to store that value, which is a subtype of Integer, which is of platform-dependent range – in this case, it is probably 32-bit, but since it is signed, its range goes only up to 2**31 - 1. This would suffice in theory, since the largest unicode code point is 0x10ffff, but AdaYaml needs to catch cases that exceed this range.
… and attached to https://github.com/yaml/AdaYaml/issues/4
STORAGE_ERROR : stack overflow or erroneous memory access
… and he created issue https://github.com/yaml/AdaYaml/issues/6 and changed the parsing mode of nested structures to avoid stack overflows (no more recursion).
There were also some “hangs”: AFL monitors the execution time of every test case, and flags large timeouts as hangs, to be inspected separately from crashes. Felix took the examples with a long execution time, and found an issue with the hashing of nodes.
With all those error cases, Felix created an issue that references all the individual issues, and corrected them.
After all the corrections, Felix gave me a analysis of the usefulness of the test:
Your findings mirror the test coverage of the AdaYaml modules pretty well:
There was no bug in the parser, as this is the most well-tested module. One bug each was found in the lexer and the text memory management, as these modules do have high test coverage, but only because they are needed for the parser tests. And then three errors in the DOM code as this module is almost completely untested.
After reading a first draft of this blog post, Felix noted that YAML.STREAM_ERROR was in fact an unexpected error in my test program.
Also, you should not exclude Yaml.Stream_Error. This error means that a malformed event stream has been encountered. Parsing a YAML input stream or serializing a DOM structure should *always* create a valid event stream unless it raises an exception – hence getting Yaml.Stream_Error would actually show that there's an internal error in one of those components. [...] Yaml.Stream_Error would only be an error with external cause if you generate an event stream manually in your code.
I filtered this exception because I'd encountered it in the test suite available in the AdaYaml github repository (it is in fact a copy of the reference yaml test-suite). I wanted to use the complete test suite as a starting corpus, but examples 8G76 and 98YD crashed and it prevented me from starting the fuzzing session, so instead of removing the crashing test cases, I filtered out the exception...
The fact that 2 test cases from the YAML test suite make my simple program crash is interesting, but can we find more cases ?
I removed those 2 files from the initial corpus, and I focused the small test program on finding cases that crash on a YAML.STREAM_ERROR:
exception
when Occurence : others =>
declare
N : constant String := Ada.Exceptions.Exception_Name (Occurence);
begin
Ada.Text_IO.Put_Line (Ada.Exceptions.Exception_Information (Occurence));
if N = "YAML.STREAM_ERROR" then
GNAT.Exception_Actions.Core_Dump (Occurence);
end if;
end Yaml_Test;In less than 5 minutes, AFL finds 5 categories of crashes:
- raised YAML.STREAM_ERROR : Unexpected event (expected document end): ALIAS
- raised YAML.STREAM_ERROR : Unexpected event (expected document end): MAPPING_START
- raised YAML.STREAM_ERROR : Unexpected event (expected document end): SCALAR
- raised YAML.STREAM_ERROR : Unexpected event (expected document end): SEQUENCE_START
- raised YAML.STREAM_ERROR : Unexpected event (expected document start): STREAM_END
Felix was quick to answer:
Well, seems like you've found a bug in the parser. This looks like the parser may generate some node after the first root node of a document, although a document always has exactly one root node. This should never happen; if the YAML contains multiple root nodes, this should be a Parser_Error.
I opened a new issue about this, to be checked later.
Fuzzing GNATCOLL.JSON
JSON parsers are a common fuzzing target, not that different from YAML. This could be interesting.
Following a similar pattern as other fuzzing sessions, let’s first build a simple unit test that reads and parses an input file given at the command-line (first argument), using GNATCOLL.JSON (https://github.com/AdaCore/gnatcoll-core/blob/master/src/gnatcoll-json.ads). This time I massaged one of the unit tests into a simple “read a JSON file all in memory, decode it and print it” test program, that we’ll use for fuzzing.
Note: for the exercise here I used GNATCOLL GPL 2016, because that's what I was using for a personal project. You should probably use the latest version when you do this kind of testing, at least before you report your findings.
The test program is very simple:
procedure JSON_Fuzzing_Test is
Filename : constant String := Ada.Command_Line.Argument (1);
JSON_Data : Unbounded_String := File_IO.Read_File (Filename);
begin
declare
Value : GNATCOLL.JSON.JSON_Value :=
GNATCOLL.JSON.Read (Strm => JSON_Data,
Filename => Filename);
begin
declare
New_JSON_Data : constant Unbounded_String :=
GNATCOLL.JSON.Write (Item => Value, Compact => False);
begin
File_IO.Write_File (File_Name => "out.json",
File_Contents => New_JSON_Data);
end;
end;
end JSON_Fuzzing_Test;The GPR file is simple with a twist : to make sure we compile this program with gnatcoll, and that when we’ll use afl-gcc we’ll compile the library code with our substitution compiler, we’ll “with” the actual “gnatcoll_full.gpr” (actual gnatcoll source code !) and not the one for the compiled library.
Then we build the project in "debug" mode, to get all the runtime checks available:
gprbuild -p -P gnat_json_fuzzing_test.gpr -XGnatcoll_Build=Debug
Then I tried to find a test corpus. One example is https://github.com/nst/JSONTestSuite cited in “Parsing JSON is a minefield”. There’s a test_parsing folder there that contains 318 test cases.
Trying to run them first on the new simple test program shows already several "crash" cases:
nice GNATCOLL.JSON.INVALID_JSON_STREAM exceptions
Numerical value too large to fit into an IEEE 754 float
Numerical value too large to fit into a Long_Long_Integer
Unexpected token
Expected ',' in the array value
Unfinished array, expecting ending ']'
Expecting a digit after the initial '-' when decoding a number
Invalid token
Expecting digits after 'e' when decoding a number
Expecting digits after a '.' when decoding a number
Expected a value after the name in a JSON object at index N
Invalid string: cannot find ending "
Nothing to read from stream
Unterminated object value
Unexpected escape sequence
… which is fine, since you’ll expect this specific exception when parsing user-provided JSON.
Then I got to:
raised ADA.STRINGS.INDEX_ERROR : a-strunb.adb:1482
n_string_1_surrogate_then_escape_u1.json
n_string_1_surrogate_then_escape_u.json
n_string_invalid-utf-8-in-escape.json
n_structure_unclosed_array_partial_null.json
n_structure_unclosed_array_unfinished_false.json
n_structure_unclosed_array_unfinished_true.json
For which I opened https://github.com/AdaCore/gnatcoll-core/issues/5
raised CONSTRAINT_ERROR : bad input for 'Value: "16#??????"]#"
n_string_incomplete_surrogate.json
n_string_incomplete_escaped_character.json
n_string_1_surrogate_then_escape_u1x.json
For which I opened https://github.com/AdaCore/gnatcoll-core/issues/6
- … and STORAGE_ERROR : stack overflow or erroneous memory access
- n_structure_100000_opening_arrays.json
This last one can be worked around using with ulimit -s unlimited (so, removing the limit of stack size). Still, beware of your stack when parsing user-provided JSON. For AdaYaml similar problems appeared, and were robustified, and I’m not sure whether this potential “denial of service by stack overflow” should be classified as a bug, it’s at least something to know when using GNATCOLL.JSON on user-provided JSON data (I’m guessing most API endpoints these days).
Those exceptions are the ones you don’t expect, and maybe didn’t put a catch-all there. A clean GNATCOLL.JSON.INVALID_JSON_STREAM exception might be better.
Note: on all those test cases, I didn’t check whether the results of the tests were OK. I just checked for crashes. It might be very interesting to check the corrected of GNATCOLL.JSON against this test suite.
Now let’s try through fuzzing to find more cases where you don’t get a clean GNATCOLL.JSON.INVALID_JSON_STREAM.
The first step is adding a final “catch-all” exception handler to abort only on unwanted exceptions (not all of them):
exception
-- we don’t want to abort on a “controlled” exception
when GNATCOLL.JSON.INVALID_JSON_STREAM =>
null;
when Occurence : others =>
Ada.Text_IO.Put_Line
("exception occured for " & Filename
& " [" & Ada.Exceptions.Exception_Name (Occurence)
& "] [" & Ada.Exceptions.Exception_Message (Occurence)
& "] [" & Ada.Exceptions.Exception_Information (Occurence) & "]");
GNAT.Exception_Actions.Core_Dump (Occurence);
end JSON_Fuzzing_Test;And then clean the generated executable:
gprclean -r -P gnat_json_fuzzing_test.gpr -XGnatcoll_Build=Debug
Then rebuild it using afl-gcc:
gprbuild --compiler-subst=Ada,/home/lionel/afl/afl-2.51b/afl-gcc -p -P gnat_json_fuzzing_test.gpr -XGnatcoll_Build=Debug
Then we generate an input corpus for AFL, by keeping only the files that didn’t generate a call to abort() with the new JSON_Fuzzing_Test test program.
On first launch (AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=ON /home/lionel/aws/afl/afl-2.51b/afl-fuzz -m 1024 -i input -o output ../json_fuzzing_test @@), afl-fuzz complains:
[*] Attempting dry run with 'id:000001,orig:i_number_huge_exp.json'...
[-] The program took more than 1000 ms to process one of the initial test cases.
This is bad news; raising the limit with the -t option is possible, but
will probably make the fuzzing process extremely slow.
If this test case is just a fluke, the other option is to just avoid it
altogether, and find one that is less of a CPU hog.
[-] PROGRAM ABORT : Test case 'id:000001,orig:i_number_huge_exp.json' results in a timeout
Location : perform_dry_run(), afl-fuzz.c:2776… and it’s true, the i_number_huge_exp.json file takes a long time to be parsed:
[lionel@lionel fuzzing-session]$ time ../json_fuzzing_test input/i_number_huge_exp.json input/i_number_huge_exp.json:1:2: Numerical value too large to fit into an IEEE 754 float real 0m7.273s user 0m3.717s sys 0m0.008s
My machine isn’t fast, but still, this is a denial of service waiting to happen. I opened a ticket just in case.
Anyway let’s remove those input files that gave a timeout before we even started the fuzzing (the other ones are n_structure_100000_opening_arrays.json and n_structure_open_array_object.json).
During this first afl-fuzz run, in the start phase, a warning appears a lot of times:
[!] WARNING: No new instrumentation output, test case may be useless.
AFL looks through the whole input corpus, and checks whether input files have added any new basic block coverage to the already tested examples (also from the input corpus).
The initial phase ends with:
[!] WARNING: Some test cases look useless. Consider using a smaller set. [!] WARNING: You probably have far too many input files! Consider trimming down.
To be the most efficient, afl-fuzz needs the slimmest input corpus with the highest basic block coverage, the most representative of all the OK code paths, and the least redundant possible. You can look through the afl-cmin and afl-tmin tools to minimize your input corpus.
For this session, let’s keep the test corpus as it is (large and redundant), and start the fuzzing session.
In the first seconds of fuzzing, we already get the following state:

Already 3 crashes, and 2 “hangs”. Looking through those, it seems afl-fuzz already found by itself examples of “ADA.STRINGS.INDEX_ERROR : a-strunb.adb:1482” and “CONSTRAINT_ERROR : bad input for 'Value: "16#?????”, although I removed from the corpus all files that showed those problems.
Same thing with the “hang”, afl-fuzz found an example of large float number, although I removed all “*_huge_*” float examples.
Let’s try and focus on finding something else than the ones we know.
I added the following code in the top-level exception handler:
when Occurence : others =>
declare
Text : constant String := Ada.Exceptions.Exception_Information (Occurence);
begin
if Ada.Strings.Fixed.Index (Source => Text, Pattern => "bad input for 'Value:") /= 0 then return;
elsif Ada.Strings.Fixed.Index (Source => Text, Pattern => "a-strunb.adb:1482") /= 0 then return;
end if;
end;It’s very hacky but it’ll remove some parasites (i.e. the crashes we know) from the crash bin.
Let’s restart the fuzzing session (remove the output/ directory, recreate it, and call afl-fuzz again).
Now after 10 minutes, no crash had occured, so I let the fuzzer run for 2 days straight, and it didn’t find any crash or hang other than the ones already triggered by the test suite.
It did however find some additional stack overflows (with examples that open a lot of arrays) even though I had put 1024m as a memory limit for afl-fuzz… Maybe something to look up...
What next?
Let's start fuzzing your favorite project, and report your results.
If you want to dive deeper in the subject of fuzzing with AFL, here's a short reading list for you:
- For language or grammar-based parsers there's a mode where you can give afl-fuzz a token dictionnary.
- Even simpler, if you have an extensive test case list, you can use afl-cmin (a corpus minimizer) to directly fuzz your parser or application efficiently, see the great success of AFL on sqlite.
- If you want to know about the fuzzing strategies adopted by afl-fuzz and how efficient they are, there's an overview on the lcamtuf blog.
- The fuzzing world took on the work of lcamtuf and you can often hear about fuzzing-specific passes in clang/llvm to help fuzzing where it's bad at (checksums, magic strings, whole-string comparisons...).
- Some people also experiment with different strategies, using AFL as a fuzzing motor: AFL -- Rare Branches or trying to improve the speed of discovery of new paths.
- There was also some work on collaboration between AFL and static analysis and symbolic execution tools. The 'Driller' paper is an example (source code on github and discussion on the afl-users list). It uses angr as its static analysis and symbolic execution driver.
- There's a lot of tooling around afl-fuzz: aflgo directs the focus of a fuzzing session to specific code parts, and Pythia helps evaluate the efficiency of your fuzzing session. See also afl-cov for live coverage analysis.
If you find bugs, or even just perform a fuzzing pass on your favorite open-source software, don't hesitate to get in touch with the maintainers of the project. From my experience, most of the time, maintainers will be happy to get free testing. Even if it's just to say that AFL didn't find anything in 3 days... It's already a badge of honor :-).
Thanks:
Many thanks to Yannick Moy that sparked the idea of this blog post after I talked his ear off for a year (was it two?) about AFL and fuzzing in Ada, and helped me proof-read it. Thanks to Gautier and Felix who were very reactive and nice about the reports, and who took some time to read drafts of this post. All your suggestions were very helpful.